检测点
青少年编程
课程设计
MQTT
kinect
低代码
g++
网站安全防护
机顶盒ROM
koa
TFT图片提取
kingbase
addWaiter
BeautifulSoup库
web结课作业的源码
hotseat图标数量
DSP
指纹识别
异常处理
Go语言
深度强化学习
2024/4/12 9:52:21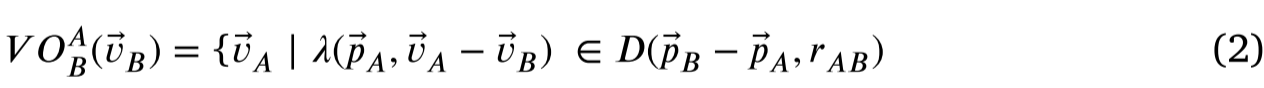
船舶自动驾驶避撞规则
1无人船避碰阶段
如图1所示。 第一阶段:感知阶段。使用雷达、AIS、激光雷达和视觉传感器等感知传感器进行障碍物检测。利用感知到的信息,获得障碍物的运动信息。 第二阶段:决策阶段。利用障碍物的运动信息做出避免冲突的决策。在这一阶段&am…

深度强化学习调参技巧
在深度强化学习中,调参是一个非常重要的任务,它直接影响到模型的性能和收敛速度。下面是一些常用的深度强化学习调参技巧: 选择合适的环境和任务: 首先要确保选择的环境和任务适合深度强化学习。不同的环境和任务对算法的表现有着不同的要求,因此需要根据具体情况选择合适…
【深度强化学习】(3) Policy Gradients 模型解析,附Pytorch完整代码
大家好,今天和各位分享一下基于策略的深度强化学习方法,策略梯度法是对策略进行建模,然后通过梯度上升更新策略网络的参数。我们使用了 OpenAI 的 gym 库,基于策略梯度法完成了一个小游戏。完整代码可以从我的 GitHub 中获得&…

深入理解强化学习——强化学习智能体的四要素:策略(Policy)
分类目录:《深入理解强化学习》总目录 相关文章: 强化学习智能体的四要素:策略(Policy) 强化学习智能体的四要素:收益信号(Revenue Signal) 强化学习智能体的四要素:价…
Python-DQN代码阅读(11)
1.代码
1.1代码阅读
tf.compat.v1.reset_default_graph() # 重置 TensorFlow 的默认计算图# Q 和 target 网络
q_net QNetwork(scope"q", VALID_ACTIONSVALID_ACTIONS) # 创建 Q 网络
target_net QNetwork(scope"target_q", VALID_ACTIONSVALID_ACTI…
Python-DQN代码阅读(7)
目录 1.代码
1.1设置ε值
代码总括
代码分解
1.2 设置时间步长总数
1.3主循环贯穿整个回合
1.4跟踪时间步长
1.5更新目标网络 1.代码
1.1设置ε值
代码总括
# epsilon start
if (train_or_test train):# 计算训练初期和训练后期的 epsilon 值的差值delta_epsilon1 …
Python-DQN代码阅读(6)-dpn.py
目录 1.代码
(1)导入所需要的包
(2)设置游戏并选择有效的操作
(3)设置模式(train/test)和开始迭代
(4)创建环境
代码总括:
代码分解:
(5&a…
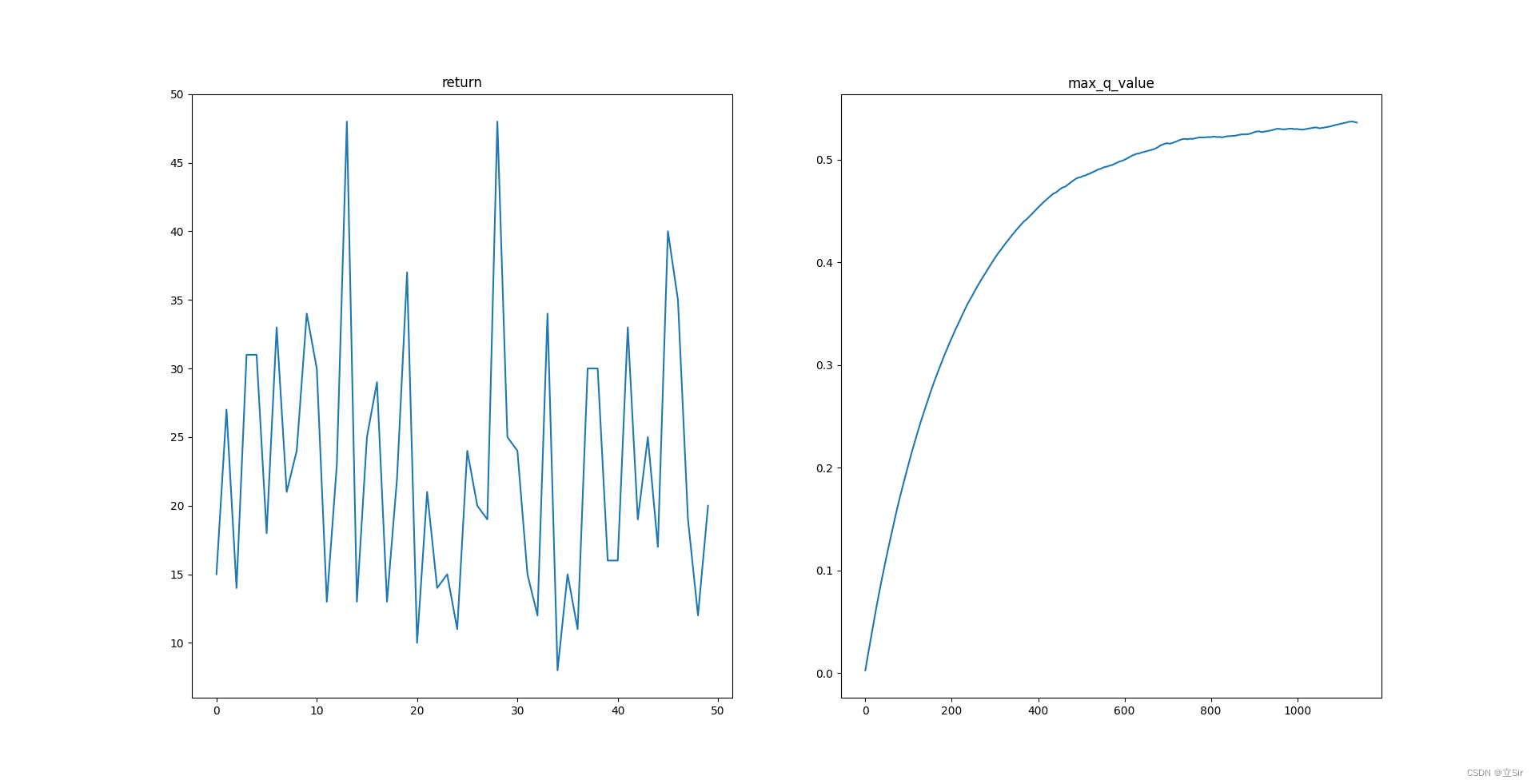
强化学习应用(六):基于Q-learning的无人机物流路径规划研究(提供Python代码)
一、Q-learning简介
Q-learning是一种强化学习算法,用于解决基于马尔可夫决策过程(MDP)的问题。它通过学习一个价值函数来指导智能体在环境中做出决策,以最大化累积奖励。
Q-learning算法的核心思想是通过不断更新一个称为Q值的…

强化学习应用(八):基于Q-learning的无人机物流路径规划研究(提供Python代码)
一、Q-learning简介
Q-learning是一种强化学习算法,用于解决基于马尔可夫决策过程(MDP)的问题。它通过学习一个价值函数来指导智能体在环境中做出决策,以最大化累积奖励。
Q-learning算法的核心思想是通过不断更新一个称为Q值的…
深入理解强化学习——学习(Learning)、规划(Planning)、探索(Exploration)和利用(Exploitation)
分类目录:《深入理解强化学习》总目录 学习
学习(Learning)和规划(Planning)是序列决策的两个基本问题。 如下图所示,在强化学习中,环境初始时是未知的,智能体不知道环境如何工作&a…

深度强化学习(二)统计、概率与随机过程普及
文章目录 随机过程集合概率随机实验与随机事件条件概率和独立事件随机变量期望和方差概率分布大数定律随机过程平稳分布 随机过程
集合 概率 随机实验与随机事件 条件概率和独立事件 随机变量 期望和方差 概率分布 大数定律 弱大数定律说明,当n趋向于无穷时&#x…
基于遗传算法GA的机器人栅格地图最短路径规划,可以自定义地图及起始点(提供MATLAB代码)
一、原理介绍
遗传算法是一种基于生物进化原理的优化算法,常用于求解复杂问题。在机器人栅格地图最短路径规划中,遗传算法可以用来寻找最优路径。
遗传算法的求解过程包括以下几个步骤:
1. 初始化种群:随机生成一组初始解&…
Python-DQN代码阅读-填充回放记忆(replay memory)
1.代码
def populate_replay_mem(sess, env, state_processor, replay_memory_init_size, policy, epsilon_start, epsilon_end, epsilon_decay_steps, VALID_ACTIONS, Transition):"""填充回放记忆(replay memory)的函数参数࿱…
深入理解强化学习——强化学习的历史:近代强化学习的发展
分类目录:《深入理解强化学习》总目录 在《深入理解强化学习——强化学习的历史》前面的文章中我们讨论了最优控制和试错学习学习的思想,接下来,我们将讨论一些在20世纪60年代和70年代,在试错学习计算和理论研究被相对忽视的时候&…
深入理解强化学习——马尔可夫决策过程:状态价值函数
分类目录:《深入理解强化学习》总目录 我们用 V ∗ ( s ) V^*(s) V∗(s)表示在马尔可夫决策过程中基于策略 π \pi π的状态价值函数(State-value Function),定义为从状态 s s s出发遵循策略 π \pi π能获得的期望回报࿰…
Python-DQN代码阅读(9)
目录 1.代码阅读
1.1 代码总括
1.2 代码分解
1.2.1 replay_memory.pop(0)
1.2.2 replay_memory.append(Transition(state, action, reward, next_state, done))
1.2.3 samples random.sample(replay_memory, batch_size)
1.2.4 q_values_next target_net.predict(sess,…

论文解析-基于 Unity3D 游戏人工智能的研究与应用
1.重写 AgentAction 方法
1.1 重写 AgentAction 方法 这段代码是一个重写了 AgentAction 方法的方法。以下是对每行代码解释:
①public override void AgentAction(float[] vectorAction)
这行代码声明了一个公共的、重写了父类的 AgentAction 方法的方法。它接受…
self-attention mechanism DQN 算法和DQN算法的区别在哪
self-attention mechanism DQN 算法与标准的 DQN 算法之间的主要区别在于其在网络结构中引入了自注意力机制(self-attention mechanism)。下面是两者之间的主要区别: 网络结构: 标准的 DQN 通常使用深度神经网络(如卷积…
深度强化学习(一)常识性普及
文章目录 机器学习、强化学习、深度学习的侧重点强化学习的简介强化学习的主要特征强化学习和机器学习的关系强化学习的发展历史 深度强化学习 一些参考的资料: 蘑菇书:https://datawhalechina.github.io/easy-rl/#/chapter1/chapter1 源代码:…
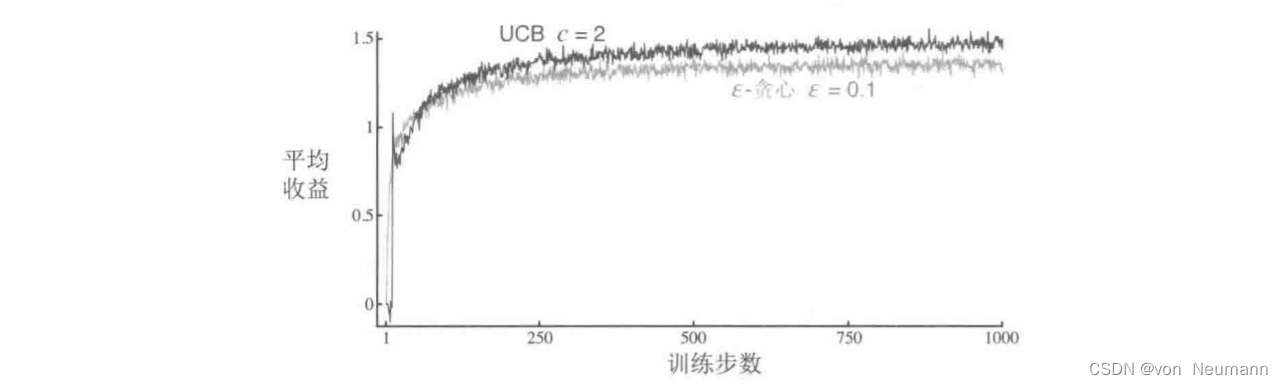
深入理解强化学习——多臂赌博机:基于置信度上界的动作选择
分类目录:《深入理解强化学习》总目录 因为对动作—价值的估计总会存在不确定性,所以试探是必须的。贪心动作虽然在当前时刻看起来最好,但实际上其他一些动作可能从长远看更好。 ϵ − \epsilon- ϵ−贪心算法会尝试选择非贪心的动作…

深入理解强化学习——多臂赌博机:基础知识
分类目录:《深入理解强化学习》总目录 强化学习与其他机器学习方法最大的不同,就在于前者的训练信号是用来评估给定动作的好坏的,而不是通过给出正确动作范例来进行直接的指导。这使得主动地反复试验以试探出好的动作变得很有必要。单纯的“评…
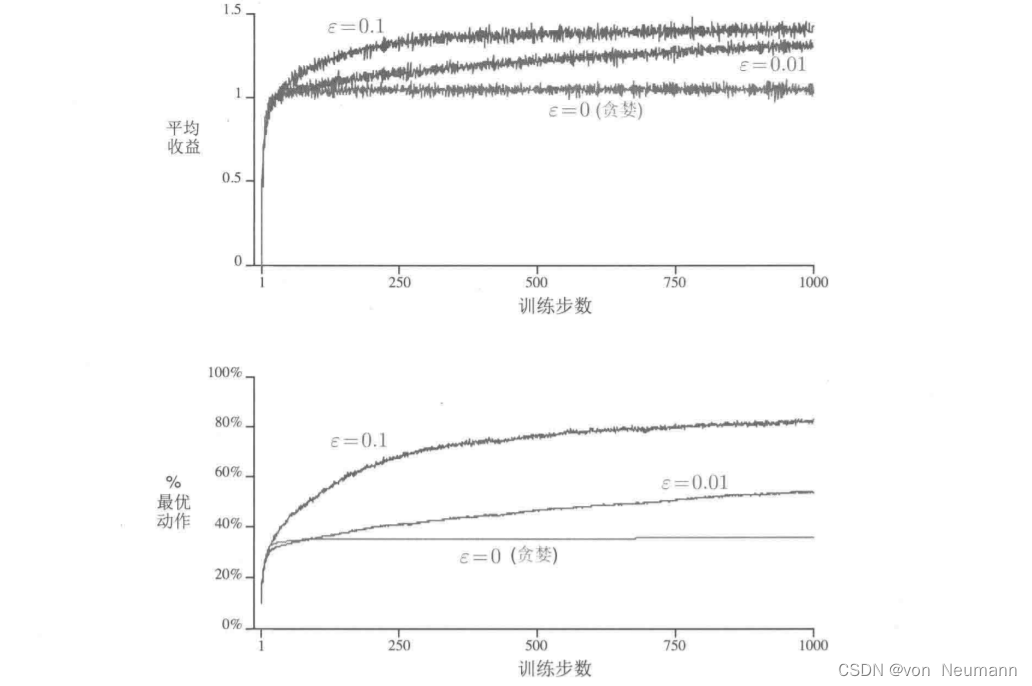
深入理解强化学习——多臂赌博机:10臂测试平台
分类目录:《深入理解强化学习》总目录 为了大致评估贪心方法和 ϵ − \epsilon- ϵ−贪心方法相对的有效性,我们将它们在一系列测试问题上进行了定量比较。这组问题是2000个随机生成的 k k k臂赌博机问题,且 k 10 k10 k10。在每一个赌博机问…
深入理解强化学习——多臂赌博机:上下文相关的赌博机(关联搜索任务)
分类目录:《深入理解强化学习》总目录 《深入理解强化学习——多臂赌博机》系列文章到此为止,只考虑了非关联的任务,对它们来说,没有必要将不同的动作与不同的情境联系起来。在这些任务中,当任务是平稳的时候ÿ…
精进语言模型:探索LLM Training微调与奖励模型技术的新途径
大语言模型训练(LLM Training)
LLMs Trainer 是一个旨在帮助人们从零开始训练大模型的仓库,该仓库最早参考自 Open-Llama,并在其基础上进行扩充。
有关 LLM 训练流程的更多细节可以参考 【LLM】从零开始训练大模型。
使用仓库之…
Unity-ML-Agents注意事项及报错、警告等解决方式
1.注意事项
1.1 ml-agents 0.28.0找不到Scripts/Brain组件?
在 ml-agents 0.16.0 版本中,Unity 中的 ML-Agents 插件中包含了名为 Brain 的组件,用于控制智能体的决策过程。然而,在 ml-agents 0.28.0 版本中,该组件已…
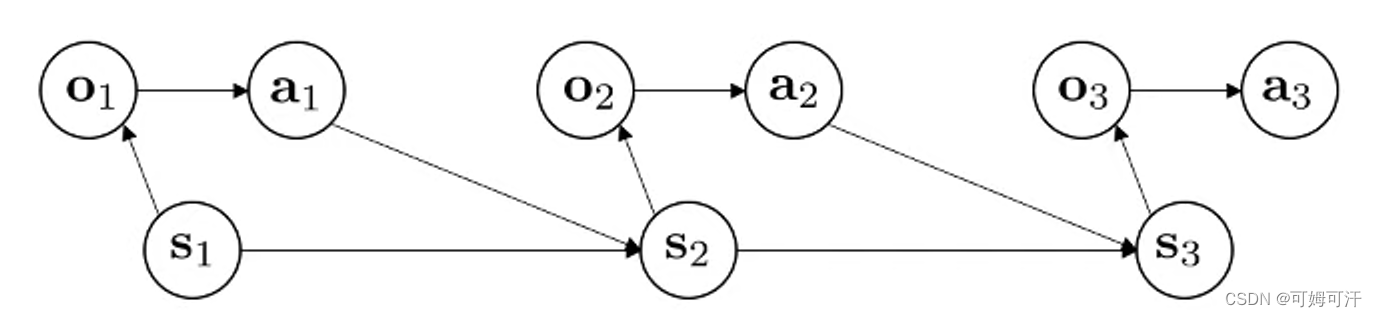
Deep Reinforment Learning Note 1
文章目录 Terminology Terminology
st : stateot : observationat : action π θ ( a t ∣ o t ) \pi_\theta (a_t | o_t) πθ(at∣ot) : policy π θ ( a t ∣ s t ) \pi_\theta (a_t | s_t) πθ(at∣st) : policy (fully observed) Observation result from…
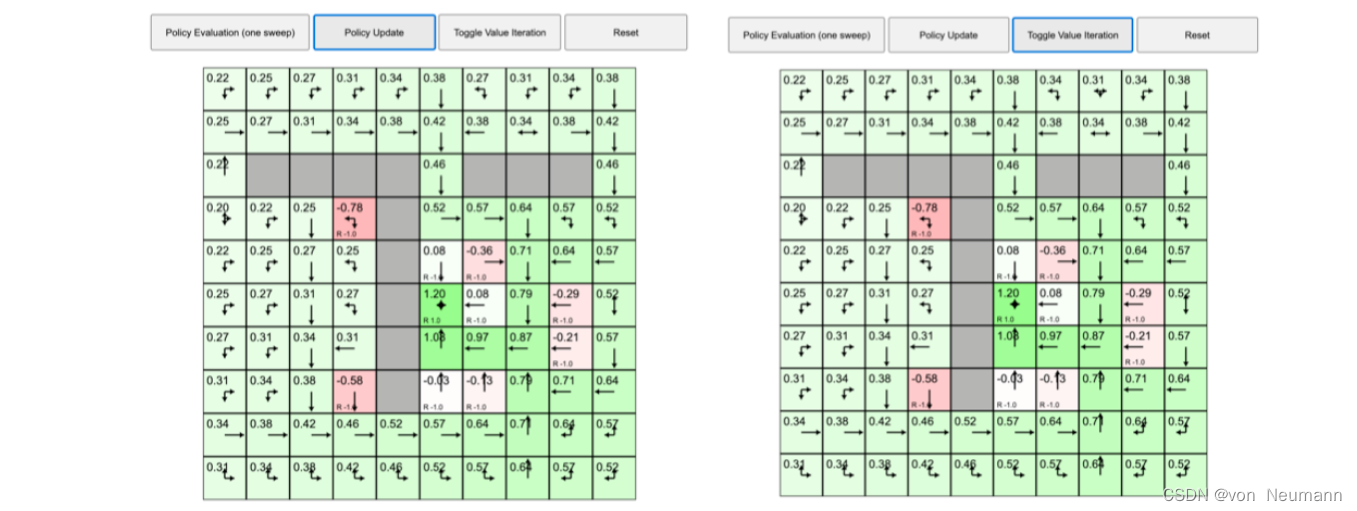
深入理解强化学习——马尔可夫决策过程:策略迭代与价值迭代的区别
分类目录:《深入理解强化学习》总目录 我们来看一个马尔可夫决策过程控制的动态演示,下图所示为网格世界的初始化界面: 首先我们来看看策略迭代,之前的例子在每个状态都采取固定的随机策略,每个状态都以0.25的概率往上…
Python-DQN-L1、L2和Huber损失
1.L1损失
L1损失,也称为平均绝对误差(Mean Absolute Error,MAE),是一种在回归问题中使用的损失函数,用于衡量预测值与实际值之间的绝对差异。
L1损失的数学定义如下: L1损失 |预测值 - 实际值…
![深入理解强化学习——马尔可夫决策过程:占用度量-[基础知识]](https://img-blog.csdnimg.cn/direct/c2cba3d315284b52a5b67830ab89b722.png)
深入理解强化学习——马尔可夫决策过程:占用度量-[基础知识]
分类目录:《深入理解强化学习》总目录 文章《深入理解强化学习——马尔可夫决策过程:贝尔曼期望方程-[基础知识]》中提到,不同策略的价值函数是不一样的。这是因为对于同一个马尔可夫决策过程,不同策略会访问到的状态的概率分布是…

【深度学习】强化学习(五)深度强化学习
文章目录 一、强化学习问题1、交互的对象2、强化学习的基本要素3、策略(Policy)4、马尔可夫决策过程5、强化学习的目标函数6、值函数7、深度强化学习1. 背景与动机2. 关键要素3. 成功案例4. 挑战和未来展望5. 核心概念和方法总结 一、强化学习问题 强化学…
【深度强化学习】(8) iPPO 模型解析,附Pytorch完整代码
大家好,今天和各位分享一下多智能体深度强化学习算法 ippo,并基于 gym 环境完成一个小案例。完整代码可以从我的 GitHub 中获得:https://github.com/LiSir-HIT/Reinforcement-Learning/tree/main/Model 1. 算法原理
多智能体的情形相比于单智…
深入理解强化学习——马尔可夫决策过程:价值迭代-[确认性价值迭代]
分类目录:《深入理解强化学习》总目录 如果我们知道子问题 V ∗ ( s ′ ) V^*(s) V∗(s′)的最优解,就可以通过价值迭代来得到最优的 V ∗ ( s ) V^*(s) V∗(s)的解。价值迭代就是把贝尔曼最优方程当成一个更新规则来进行,即: V …
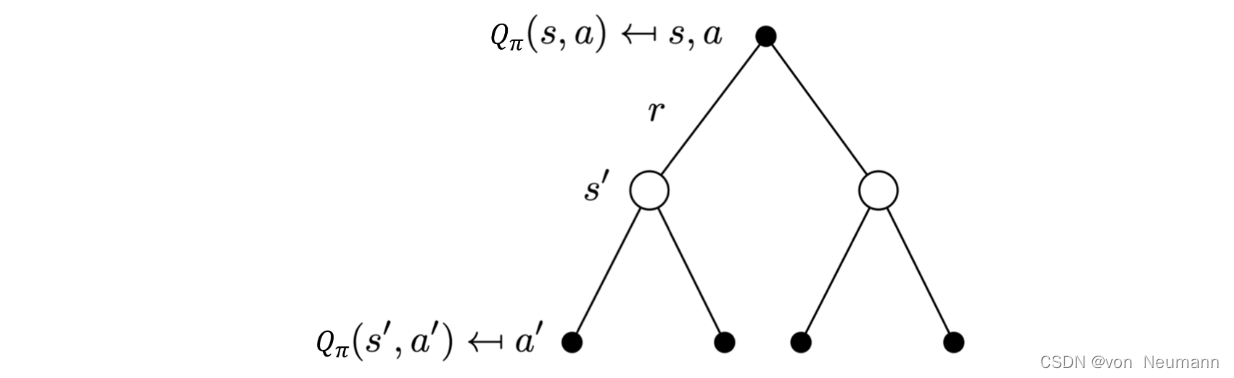
深入理解强化学习——马尔可夫决策过程:备份图(Backup Diagram)
分类目录:《深入理解强化学习》总目录 在本文中,我们将介绍备份(Backup)的概念。备份类似于自举之间的迭代关系,对于某一个状态,它的当前价值是与它的未来价值线性相关的。 我们将与下图类似的图称为备份图…

深度强化学习(三)马尔科夫决策过程
文章目录 马尔可夫过程MP马尔科夫链MC状态转移概率矩阵n步转移概率 马尔科夫链 马尔科夫奖励过程MRP奖励机制计算价值概念定义计算价值推导贝尔曼方程贝尔曼方程实际应用 参考文章:https://blog.csdn.net/taka_is_beauty/article/details/88356375 序贯决策问题是针…
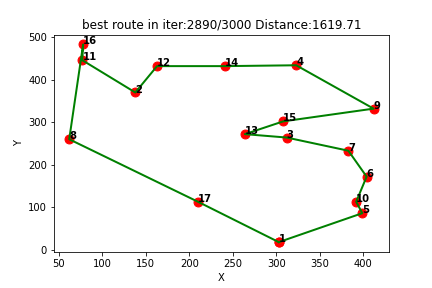
强化学习应用(一):基于Q-learning的无人机物流路径规划研究(提供Python代码)
一、Q-learning简介
Q-learning是一种强化学习算法,用于解决基于马尔可夫决策过程(MDP)的问题。它通过学习一个价值函数来指导智能体在环境中做出决策,以最大化累积奖励。
Q-learning算法的核心思想是通过不断更新一个称为Q值的…
深入理解强化学习——马尔可夫决策过程:马尔可夫奖励过程-[价值函数]
分类目录:《深入理解强化学习》总目录 在马尔可夫过程的基础上加入奖励函数和折扣因子,就可以得到马尔可夫奖励过程(Markov Reward Process)。一个马尔可夫奖励过程由 ( S , P , r , γ ) (S, P, r, \gamma) (S,P,r,γ)构成&#…
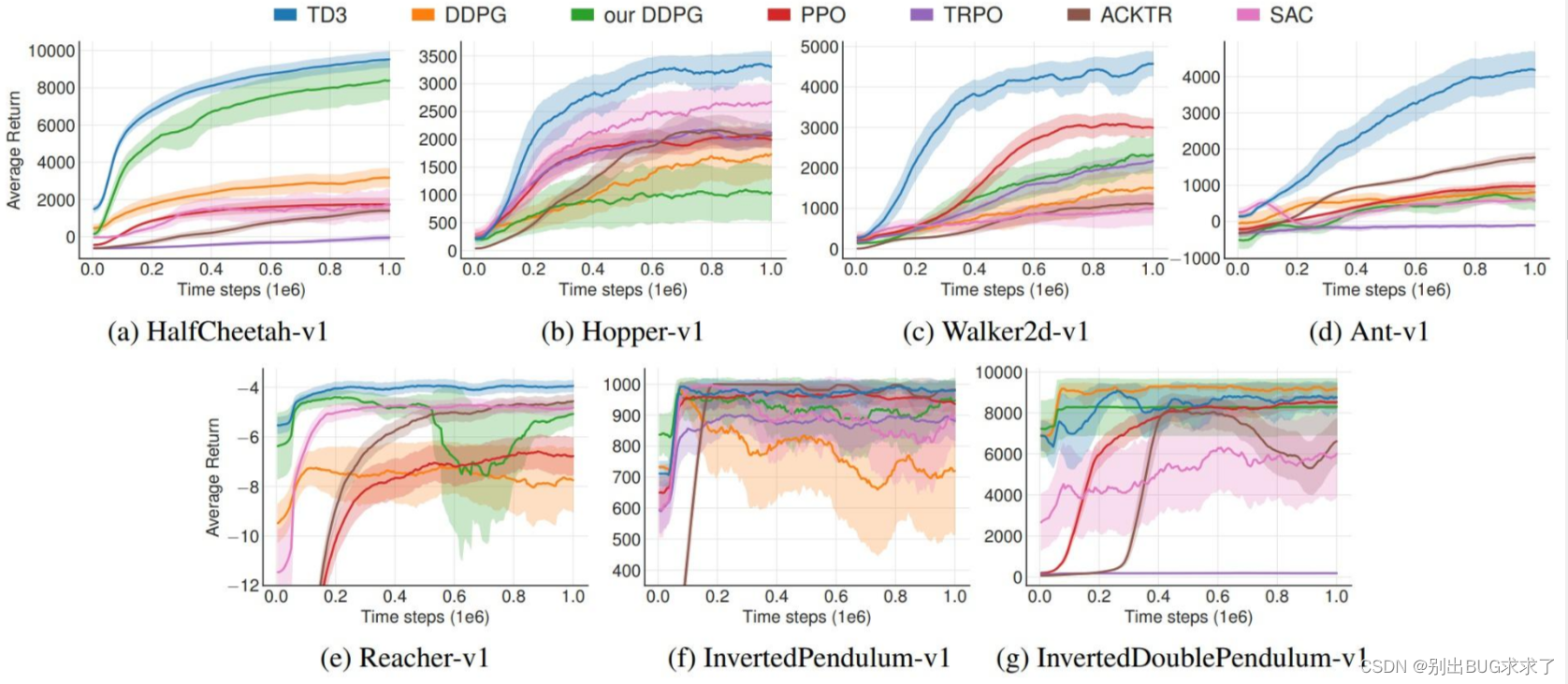
深度强化学习论文中的阴影折线图——总结和分析
前言
作为目前人工智能算法的一个重要领域,强化学习算法的表现非常出色,然而,强化学习算法的结果是出了名的不稳定:超参数的搜索空间往往非常大,算法对不同超参数都较为敏感,且哪怕仅仅只有随机数种子的不…
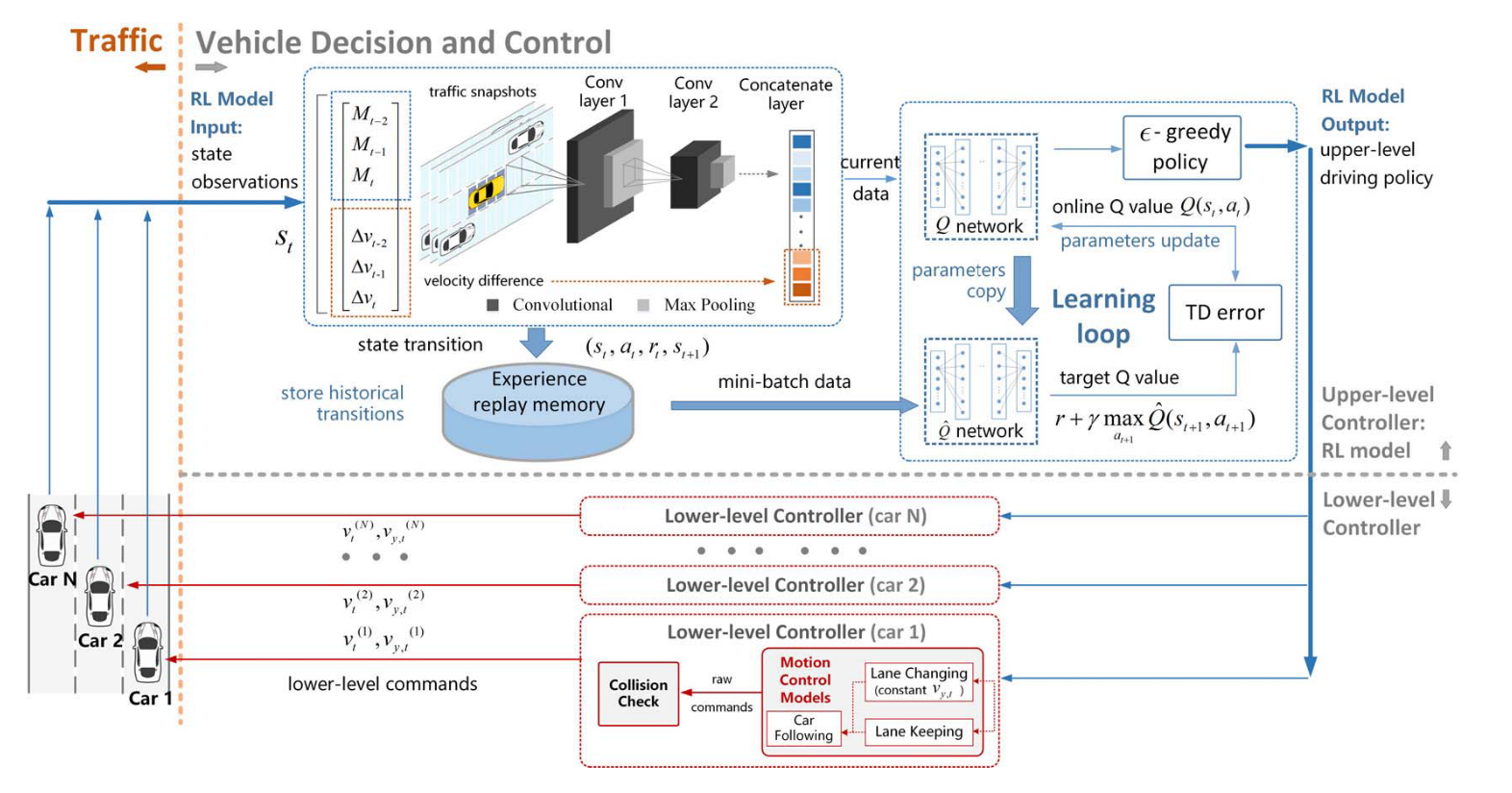
深度强化学习的变道策略:Harmonious Lane Changing via Deep Reinforcement Learning
偏理论,假设情况不易发生 摘要
多智能体强化学习的换道策略,不同的智能体在每一轮学习后交换策略,达到零和博弈。
和谐驾驶仅依赖于单个车辆有限的感知结果来平衡整体和个体效率,奖励机制结合个人效率和整体效率的和谐。
Ⅰ. 简…
Python-L1和L2正则化
1.L1和L2正则化
L1 正则化和 L2 正则化是在神经网络中常用的两种正则化技术,用于对权重参数进行惩罚,以减小过拟合现象。它们有以下联系和区别:
联系:
①L1 正则化和 L2 正则化都是在训练神经网络时添加到损失函数中的额外项&a…
Python-DQN和Dueling Network代码对比阅读(15)-model.py
1.文件修改
Dueling Network和DDQN都是三个文件,funcs.py、model.py和dueling.py或者ddpn.py。
对于funcs.py,其以前用于DDQN,所以再次使用。dueling.py代码也与ddpn.py相同(只是重命名)。因此,只需更改m…
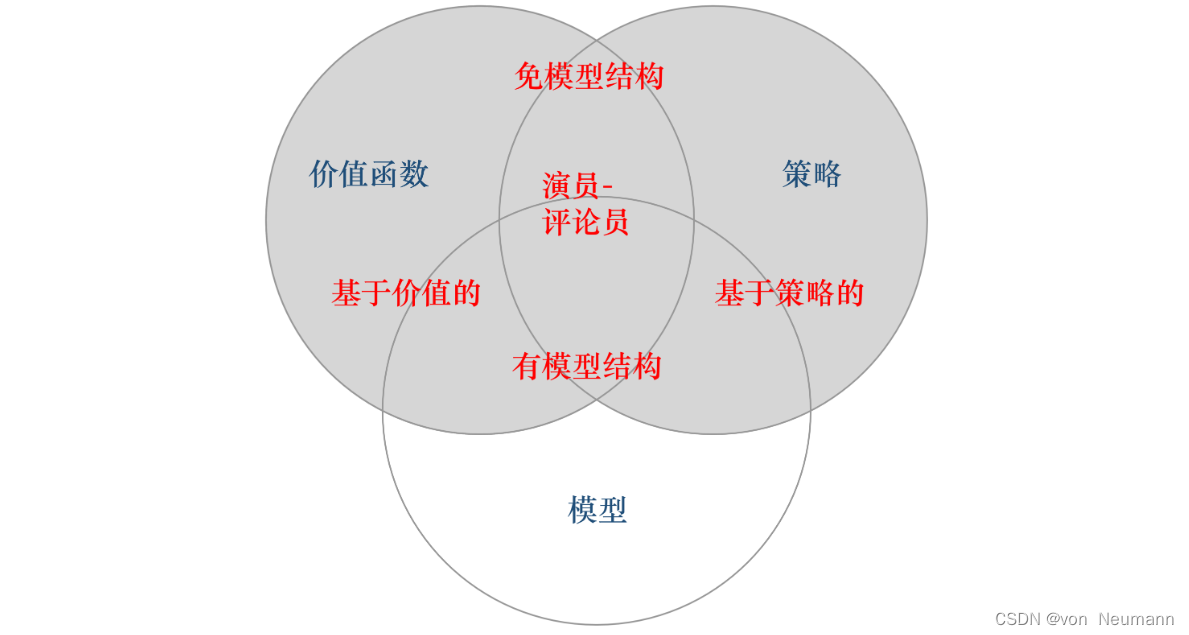
深入理解强化学习——智能体的类型:有模型强化学习智能体与免模型强化学习智能体
分类目录:《深入理解强化学习》总目录 根据智能体学习的事物不同,我们可以把智能体进行归类。基于价值的智能体(Value-based agent)显式地学习价值函数,隐式地学习它的策略。策略是其从学到的价值函数里面推算出来的。…
深入理解强化学习——强化学习智能体的四要素:价值函数(Value Function)
分类目录:《深入理解强化学习》总目录 相关文章: 强化学习智能体的四要素:策略(Policy) 强化学习智能体的四要素:收益信号(Revenue Signal) 强化学习智能体的四要素:价…
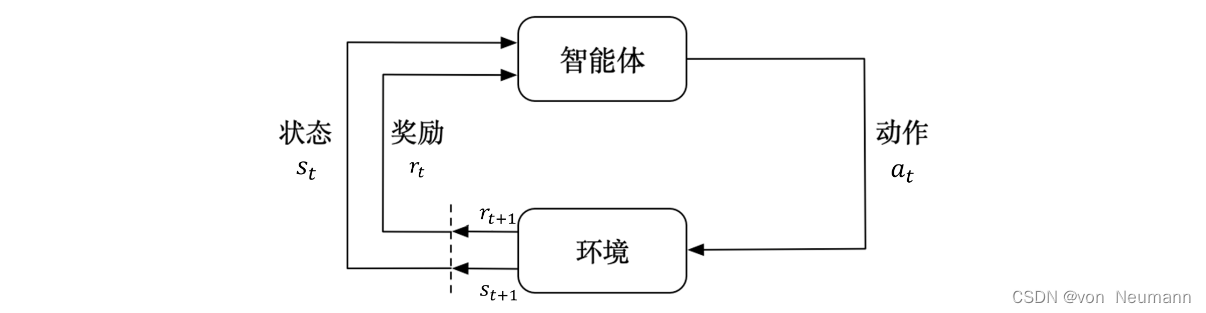
深入理解强化学习——马尔可夫决策过程:随机过程和马尔可夫性质
分类目录:《深入理解强化学习》总目录 下图介绍了强化学习里面智能体与环境之间的交互,智能体得到环境的状态后,它会采取动作,并把这个采取的动作返还给环境。环境得到智能体的动作后,它会进入下一个状态,把…
深度强化学习-DDPG代码阅读-ddpg.py(1)
目录
1.编写ddpg.py
1.1 导入需要的包和其他的python文件
1.2 定义训练函数train()
1.2.1 代码总括
1.2.2 代码分解
1.3 定义测试函数test()
1.3.1 代码总括
1.3.2 代码分解
1.4 定义主函数
1.4.1 代码总括
1.4.2 代码分解
1.5 根据需要调用训练函数或者测试函数
…

在迷宫环境中使用图像目标导向深度强化学习笔记(一)
新一年新收获,预祝大家2020年工作顺利,身体健康。
此部分作为一个节点,下面大部分时间用于期末复习,打算考完试再继续这一块的工作。
之前接触过一部分这方面知识,当时感觉用到的机会不是很大,所以就没好…

深入理解强化学习——标准强化学习和深度强化学习
分类目录:《深入理解强化学习》总目录 强化学习的历史
早期的强化学习,我们称其为标准强化学习。最近业界把强化学习与深度学习结合起来,就形成了深度强化学习(Deep ReinforcemetLearning)。因此,深度强化…

MADDPG-学习笔记(1)
文献链接:https://arxiv.org/abs/1706.02275
"Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments"(作者:Lowe, Ryan等人,2017年)
环境搭建:https://zhuanlan.zhihu.co…

粒子群优化算法(Particle Swarm Optimization,PSO)求解基于移动边缘计算的任务卸载与资源调度优化(提供MATLAB代码)
一、优化模型介绍
移动边缘计算的任务卸载与资源调度优化原理是通过利用配备计算资源的移动无人机来为本地资源有限的移动用户提供计算卸载机会,以减轻用户设备的计算负担并提高计算性能。具体原理如下: 任务卸载:移动边缘计算系统将用户的计…

中科院自动化所:基于关系图深度强化学习的机器人多目标包围问题新算法
摘要:中科院自动化所蒲志强教授团队,提出一种基于关系图的深度强化学习方法,应用于多目标避碰包围(MECA)问题,使用NOKOV度量动作捕捉系统获取多机器人位置信息,验证了方法的有效性和适应性。研究成果在2022年ICRA大会发…
无线通信:基于深度强化学习
这里写自定义目录标题 异构蜂窝网络:用户关联和信道分配a stochastic gameMulti-Agent Q-Learning MethodMulti-Agent dueling double DQN Algorithm 分布式动态下行链路波束成形Limited-Information Exchange ProtocolDistributed DRL-Based DTDE Scheme for DDBCD…
Python-代码阅读(1)-funcs.py
1.图像处理的类 ImageProcess
import numpy as np
import sys
import tensorflow as tf # 导入 TensorFlow 库,用于实现深度学习模型# convert raw Atari RGB image of size 210x160x3 into 84x84 grayscale image
class ImageProcess():def __init__(self):with …
Python-DQN代码阅读(10)
目录 1.代码
1.1 代码阅读
1.2 代码分解
1.2.1 f open("experiments/" str(env.spec.id) "/performance.txt", "a")
1.2.2 f.write(str(ep) " " str(time_steps) " " str(episode_rewards) " " str(…
五种多目标优化算法(MOGWO、MOJS、NSWOA、MOPSO、MOAHA)性能对比,包含6种评价指标,9个测试函数(提供MATLAB代码)
一、5种多目标优化算法简介
1.1MOGWO 1.2MOJS 1.3NSWOA 1.4MOPSO 1.5MOAHA 二、5种多目标优化算法性能对比
为了测试5种算法的性能将其求解9个多目标测试函数(zdt1、zdt2 、zdt3、 zdt4、 zdt6 、Schaffer、 Kursawe 、Viennet2、 Viennet3)࿰…
Python-DQN和DDQN代码对比阅读(14)-ddpn.py
DQN和DDQN都是三个文件,funcs.py、model.py和DQN.py或者DDQN.py。
两种算法的funcs.py、model.py文件完全一样,区别在第三个文件。
目录 1.代码区别
1.1 定义ALGO变量来选择算法
1.2 使用if语句对两种算法做出选择
1.2.1 DQN
1.2.2 DDQN
2.问题 1…
Python-pop()和popleft()方法
1. pop()和popleft()方法
pop() 和 popleft() 是 Python 标准库 collections 模块中 deque(双端队列)对象的方法,用于从队列中删除元素。
pop() 方法用于从队列的右侧(末尾)删除元素,并返回被删除的元素。…

强化学习应用(七):基于Q-learning的无人机物流路径规划研究(提供Python代码)
一、Q-learning简介
Q-learning是一种强化学习算法,用于解决基于马尔可夫决策过程(MDP)的问题。它通过学习一个价值函数来指导智能体在环境中做出决策,以最大化累积奖励。
Q-learning算法的核心思想是通过不断更新一个称为Q值的…
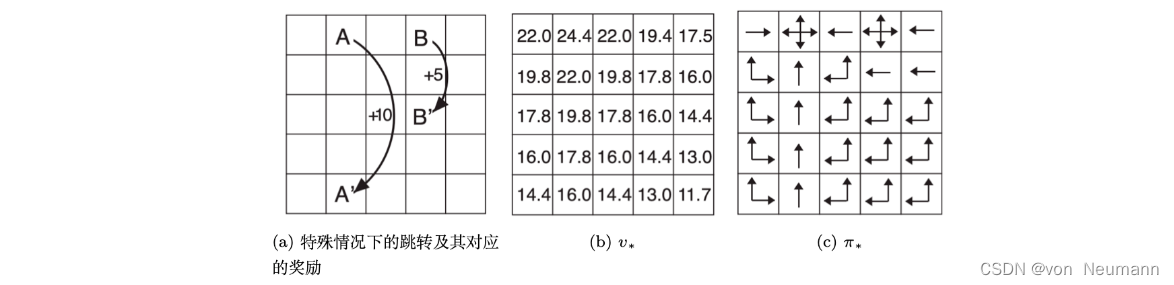
深入理解强化学习——马尔可夫决策过程:预测与控制
分类目录:《深入理解强化学习》总目录 预测(Prediction)和控制(Control)是马尔可夫决策过程里面的核心问题。预测(评估一个给定的策略)的输入是马尔可夫决策过程 < S , A , R , P , γ > …
Python-代码阅读-将一个神经网络模型的参数复制到另一个模型中(2)
1.代码
def copy_model_parameters(sess, qnet1, qnet2):# 获取qnet1和qnet2中的可训练变量(参数)q1_params [t for t in tf.trainable_variables() if t.name.startswith(qnet1.scope)]q1_params sorted(q1_params, keylambda v: v.name)q2_params …
深入理解强化学习——强化学习的历史:试错学习
分类目录:《深入理解强化学习》总目录 让我们现在回到另一条通向现代强化学习领域的主线上,它的核心则是试错学习思想。我们在这里只对要点做概述,《深入理解强化学习》系列后面的文章会更详细地讨论这个主题。根据美国心理学家R.S.woodworth…
Python-DQN代码阅读-初始化经验回放记忆(replay memory)(4)
1.代码
def populate_replay_mem(sess, env, state_processor, replay_memory_init_size, policy, epsilon_start, epsilon_end, epsilon_decay_steps, VALID_ACTIONS, Transition):# 重置环境并获取初始状态state env.reset()# 使用状态处理器对初始状态进行预处理state st…

深入理解强化学习——强化学习智能体的四要素:模型(Model)
分类目录:《深入理解强化学习》总目录 相关文章: 强化学习智能体的四要素:策略(Policy) 强化学习智能体的四要素:收益信号(Revenue Signal) 强化学习智能体的四要素:价…
深入理解强化学习——强化学习的复杂性、局限性和适用范围
分类目录:《深入理解强化学习》总目录 强化学习的复杂性
首先要注意的是,强化学习中的观察结果取决于智能体选择的动作,某种程度上可以说是动作导致的结果。如果智能体选择了无用的动作,观察结果不会告诉你做错了什么或如何选择动…

【深度强化学习】目前落地的挑战与前沿对策
到目前为止,深度强化学习最成功、最有名的应用仍然是 Atari 游戏、围棋游戏等。即使深度强化学习有很多现实中的应用,但其中成功的应用并不多。为什么呢?本文总结目前的挑战。 目录 所需的样本数量太大探索阶段代价太大超参数的影响非常大稳定…
【from PIL import Image】PIL库和Image的功能及用法
from PIL import Image代码 from PIL import Image 是 Python 中导入 PIL 库中的 Image 模块。PIL 是 Python Imaging Library 的缩写,它是 Python 中用于图像处理的一个强大的库。而 Image 模块则是 PIL 库中的一个子模块,提供了处理图像的各种功能。
…

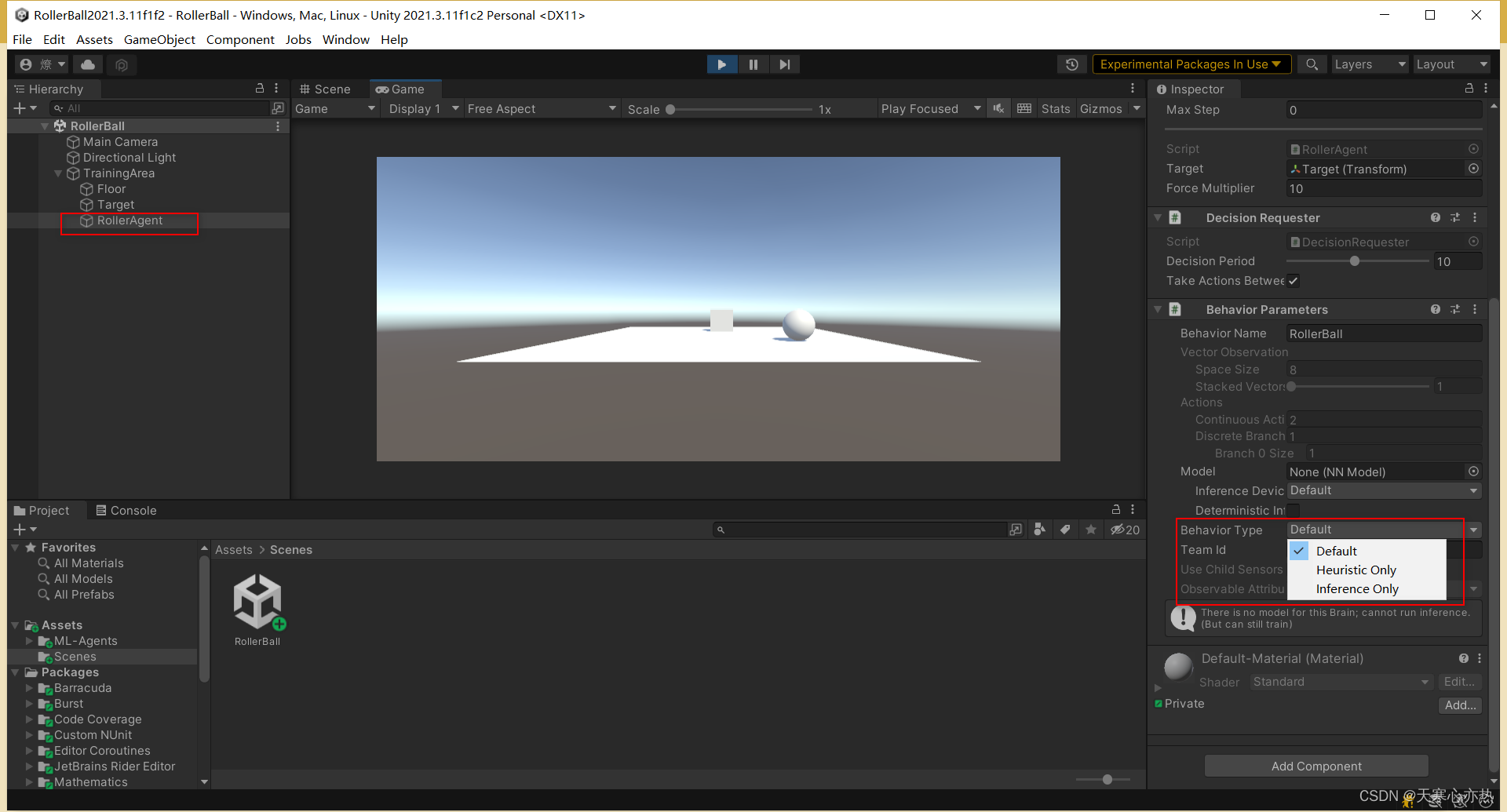
Unity-ML-Agents-代码解读-RollerBall
使用版本:https://github.com/Unity-Technologies/ml-agents/releases/tag/release_19
文件路径:ml-agents-release_19/docs/Learning-Environment-Create-New.md
20和19的在rollerBall上一样:https://github.com/Unity-Technologies/ml-ag…
深入理解强化学习——强化学习的局限性与适用范围
分类目录:《深入理解强化学习》总目录 强化学习十分依赖“状态”这个概念,它既作为策略和价值函数的输人,又同时作为模型的输人与输出。一般,我们可以把状态看作传递给智能体的一种信号,这种信号告诉智能体“当前环境如…
深入理解强化学习——多臂赌博机:梯度赌博机算法的数学证明
分类目录:《深入理解强化学习》总目录 通过将梯度赌博机算法理解为梯度上升的随机近似,我们可以深人了解这一算法的本质。在精确的梯度上升算法中,每一个动作的偏好函数 H t ( a ) H_t(a) Ht(a)与增量对性能的影响成正比: H t …
深入理解强化学习——马尔可夫决策过程:马尔可夫奖励过程-[计算马尔可夫奖励过程价值的蒙特卡洛方法]
分类目录:《深入理解强化学习》总目录 文章《[深入理解强化学习——马尔可夫决策过程:马尔可夫奖励过程-[贝尔曼方程]]](https://machinelearning.blog.csdn.net/article/details/134407229)》介绍了计算马尔可夫奖励过程价值的解析方法,但解…
深入理解强化学习——强化学习的历史:时序差分学习
分类目录:《深入理解强化学习》总目录 相关文章: 强化学习的历史:最优控制 强化学习的历史:试错学习 强化学习的历史:试错学习的发展 强化学习的历史:K臂赌博机、统计学习理论和自适应系统 强化学习的…
深入理解强化学习——马尔可夫决策过程:马尔可夫奖励过程-[贝尔曼方程]
分类目录:《深入理解强化学习》总目录 在文章《深入理解强化学习——马尔可夫决策过程:马尔可夫奖励过程-[价值函数]》中,我们知道即时奖励的期望正是奖励函数的输出,即: E [ R t ∣ S s ] r ( s ) E[R_t|Ss]r(s) E[…
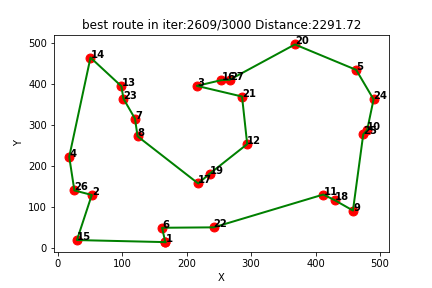
强化学习应用(四):基于Q-learning的无人机物流路径规划研究(提供Python代码)
一、Q-learning简介
Q-learning是一种强化学习算法,用于解决基于马尔可夫决策过程(MDP)的问题。它通过学习一个价值函数来指导智能体在环境中做出决策,以最大化累积奖励。
Q-learning算法的核心思想是通过不断更新一个称为Q值的…
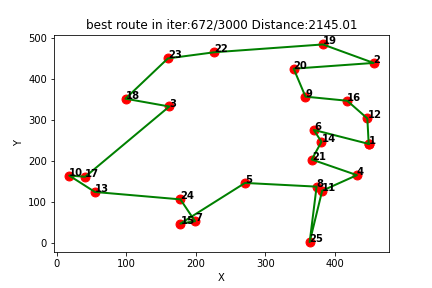
强化学习应用(二):基于Q-learning的无人机物流路径规划研究(提供Python代码)
一、Q-learning简介
Q-learning是一种强化学习算法,用于解决基于马尔可夫决策过程(MDP)的问题。它通过学习一个价值函数来指导智能体在环境中做出决策,以最大化累积奖励。
Q-learning算法的核心思想是通过不断更新一个称为Q值的…
深入理解强化学习——动作空间(Action Space)
分类目录:《深入理解强化学习》总目录 不同的环境允许不同种类的动作。在给定的环境中,有效动作的集合经常被称为动作空间(Action Space)。像雅达利游戏和围棋(Go)这样的环境有离散动作空间(Dis…
深入理解强化学习——多臂赌博机:动作一价值方法
分类目录:《深入理解强化学习》总目录 本文我们来详细分析估计动作的价值的算法。我们使用这些价值的估计来进行动作的选择,这一类方法被统称为“动作一价值方法"。如前文所述,动作的价值的真实值是选择这个动作时的期望收益。因此&…